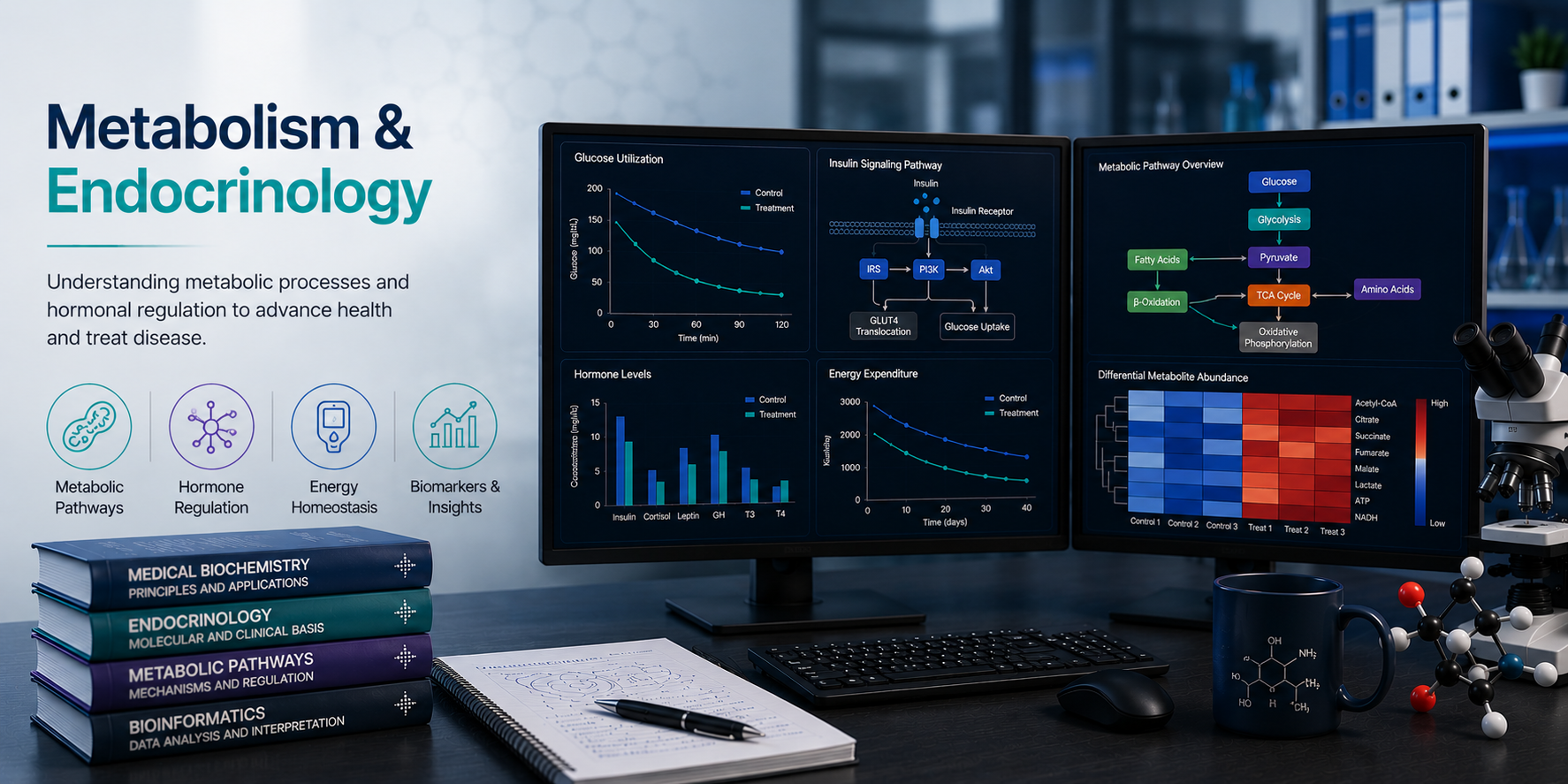
Metabolic and endocrine disorders — including diabetes, obesity, non-alcoholic fatty liver disease, thyroid dysfunction, and polycystic ovary syndrome — are among the most prevalent and burdensome conditions worldwide. Understanding their molecular underpinnings requires integrating genomic, transcriptomic, proteomic, and metabolomic data with clinical and physiological measurements. At BioinformaticsNext, we provide expert bioinformatics support for metabolism and endocrinology research, helping scientists decode the molecular drivers of metabolic disease and hormonal dysregulation at every level of biological organisation.
Bioinformatics for Metabolism & Endocrinology
Turning complex multi-omics datasets into clear, actionable biological insights.
Metabolism and endocrinology research sits at the intersection of genetics, molecular biology, physiology, and clinical medicine. The field has been transformed by high-throughput omics technologies — enabling researchers to identify disease-causing genetic variants, map dysregulated metabolic pathways, characterise hormone-responsive gene networks, and discover novel biomarkers for diagnosis and therapeutic response.
At BioinformaticsNext, we provide the computational expertise to support everything from fundamental mechanistic research to translational biomarker discovery and drug target identification.
What We Analyse
Comprehensive omics profiling across metabolic tissues, circulating biomarkers, and endocrine systems.
- Genetic variants associated with metabolic traits and endocrine disorders
- Transcriptomic changes in metabolic tissues — liver, adipose, pancreas, muscle, and thyroid
- Hormone-responsive gene networks and transcription factor regulons
- Metabolite profiles and dysregulated metabolic pathways in disease states
- Proteomic changes in plasma, tissue, and subcellular fractions
- Epigenetic regulation of metabolic gene expression
- Gut microbiome contributions to metabolic phenotypes
- Multi-omics integration for comprehensive metabolic disease characterisation
Our Metabolism & Endocrinology Services
Comprehensive bioinformatics support across the full range of omics data types relevant to metabolism and endocrinology research.
All pipelines are built on validated, peer-reviewed methods and tailored to your specific experimental design and research question.
1. Genomics & Genetic Association Analysis GWAS · PRS · MR · Rare Variants
Identifying the genetic variants that drive metabolic and endocrine disorders is a cornerstone of metabolic disease research. Our genetics service covers the complete pipeline from raw genotype data to biologically interpretable association signals.
- Genome-wide association studies (GWAS) — Quality-controlled genotype array analysis with PLINK2 and REGENIE; mixed model association testing correcting for population structure and relatedness; Manhattan and QQ plot generation
- Metabolic trait GWAS — Association analysis for BMI, fasting glucose, HbA1c, insulin resistance (HOMA-IR), lipid profiles, thyroid hormone levels, and adipokines
- Post-GWAS fine-mapping — Credible set construction and causal variant prioritisation with SuSiE and FINEMAP; colocalisation with eQTL and metabolite QTL datasets
- Polygenic risk score (PRS) construction — PRS development and validation for type 2 diabetes, obesity, dyslipidaemia, and other metabolic conditions using LDpred2 and PRSice2
- Rare variant analysis — Gene-based burden and SKAT tests for rare coding variants in metabolic disease genes; WES and WGS variant calling and annotation
- Mendelian randomisation — Two-sample MR analysis with TwoSampleMR for causal inference between metabolic exposures and disease outcomes
- Genetic correlation analysis — LD-score regression (LDSC) for estimating shared genetic architecture between metabolic traits and comorbid conditions
2. Transcriptomics of Metabolic Tissues RNA-seq · WGCNA · Splicing
Gene expression profiling of metabolic tissues — liver, adipose tissue, skeletal muscle, pancreatic islets, thyroid, and adrenal glands — reveals the transcriptional programmes underlying metabolic homeostasis and disease.
- Bulk RNA-seq analysis — STAR alignment, Salmon quantification; differential gene expression with DESeq2, edgeR, and limma-voom across metabolic conditions, treatments, or timepoints
- Pathway enrichment analysis — GSEA, fGSEA, and clusterProfiler with KEGG, Reactome, GO, and WikiPathways metabolic pathway gene sets
- Hormone-responsive gene networks — Identification of insulin, glucagon, thyroid hormone, cortisol, oestrogen, and androgen-regulated transcriptional programmes
- Co-expression network analysis — WGCNA for metabolic module identification; hub gene discovery and module-trait correlation with clinical metabolic parameters
- Alternative splicing analysis — rMATS and SUPPA2 for exon-level splicing changes in metabolic genes; isoform switching analysis with IsoformSwitchAnalyzeR
- Non-coding RNA profiling — lncRNA, miRNA, and circRNA differential expression and target prediction in metabolic disease contexts
3. Single-Cell RNA Sequencing in Metabolic Research Pancreas · Liver · Adipose · scRNA-seq
Single-cell transcriptomics has transformed our understanding of cellular heterogeneity in metabolic organs — revealing distinct beta cell subtypes in the pancreas, lipid-associated macrophages in adipose tissue, hepatocyte zonation in the liver, and rare endocrine cell populations that drive hormonal regulation.
- Pancreatic islet scRNA-seq — Alpha, beta, delta, PP, and epsilon cell identification; beta cell stress and dedifferentiation state characterisation; insulin secretion gene programme analysis
- Adipose tissue scRNA-seq — Adipocyte, preadipocyte, macrophage, and stromal vascular fraction cell-type deconvolution; lipid-associated macrophage (LAM) profiling
- Liver scRNA-seq & spatial transcriptomics — Hepatocyte zonation; Kupffer cell, stellate cell, and cholangiocyte identification; NAFLD and fibrosis cell state characterisation
- Full scRNA-seq workflow — Cell Ranger / STARsolo alignment; ambient RNA removal; doublet detection; clustering, annotation, and differential abundance testing with Seurat and Scanpy
- Trajectory & pseudotime analysis — Monocle3, scVelo, and Palantir for mapping cellular differentiation and metabolic state transitions
- Cell-cell communication — CellChat, NicheNet, and LIANA for mapping paracrine and endocrine signalling networks within metabolic organs
4. Metabolomics & Lipidomics LC-MS · GC-MS · mQTL · Pathways
Metabolomics provides a direct readout of metabolic phenotype — capturing the downstream functional consequences of genetic, transcriptional, and environmental perturbations on cellular and systemic metabolism.
- Untargeted metabolomics — LC-MS and GC-MS raw data processing with XCMS and MZmine; feature detection, peak alignment, and gap filling; adduct annotation and isotope filtering
- Targeted metabolomics — Quantitative analysis of predefined metabolite panels: amino acids, organic acids, acylcarnitines, bile acids, short-chain fatty acids, and nucleotides
- Metabolite identification — MS/MS spectral matching against HMDB, METLIN, MassBank, and LIPID MAPS; MSI confidence-level annotation
- Differential abundance analysis — Univariate testing and multivariate methods (PLS-DA, OPLS-DA) with MetaboAnalyst; FDR correction and volcano plot visualisation
- Metabolic pathway analysis — Pathway enrichment and topology analysis with MetaboAnalyst and MetExplore using KEGG, HMDB, and BioCyc databases
- Lipidomics analysis — Lipid class and species-level quantification with LipidSearch and LIQUID; differential lipid species analysis and lipidome visualisation
- Metabolite QTL (mQTL) mapping — Genetic association mapping of circulating metabolite levels; integration with GWAS signals for causal metabolic pathway identification
5. Proteomics in Metabolic Disease LFQ · TMT · Phosphoproteomics · Plasma
Proteins are the functional effectors of metabolic processes — and proteomic profiling of plasma, tissues, and organelles reveals the molecular machinery driving metabolic homeostasis and its breakdown in disease.
- Label-free quantification (LFQ) — MaxQuant and Proteome Discoverer data processing; Perseus statistical analysis; differential protein abundance between metabolic conditions
- TMT / iTRAQ-based quantitative proteomics — Isobaric labelling experiment analysis; batch correction; multi-condition comparison and time-course profiling
- Plasma proteomics — Circulating biomarker discovery for metabolic disease diagnosis and monitoring
- Phosphoproteomics & PTM analysis — Insulin signalling cascade phosphorylation profiling; kinase activity inference; AKT, mTOR, and AMPK pathway activation state mapping
- Organelle proteomics — Mitochondrial proteome analysis; electron transport chain complex composition; metabolic enzyme abundance changes in disease
- Proteome-transcriptome integration — Correlation of protein and RNA abundance changes; identification of post-transcriptionally regulated metabolic genes
6. Epigenomics of Metabolic Tissues EWAS · ChIP · ATAC · Methylation
Epigenetic mechanisms — DNA methylation, histone modification, and chromatin remodelling — play a central role in the regulation of metabolic gene expression and in mediating the long-term effects of nutritional, hormonal, and environmental exposures on metabolic phenotype.
- DNA methylation analysis — Illumina EPIC array and WGBS processing; differentially methylated region (DMR) calling with DSS and methylKit; epigenetic clock and biological age estimation
- ChIP-seq for metabolic regulators — Histone modification mapping and TF binding (PPARG, CEBPA, FOXO1, NR3C1) in metabolic tissues; peak calling (MACS3), differential binding, and motif enrichment
- ATAC-seq in metabolic tissues — Chromatin accessibility profiling in liver, adipose, and pancreatic islets; open chromatin changes in response to metabolic stimuli
- Epigenome-wide association studies (EWAS) — Methylation array-based EWAS for metabolic traits with limma and ChAMP; confounding correction for cell-type composition
- Multi-omics epigenomic integration — Joint analysis linking DNA methylation, chromatin accessibility, and gene expression changes in metabolic disease using MOFA+ and ArchR
7. Gut Microbiome & Metabolic Disease 16S · Metagenomics · Microbiome-Metabolome
The gut microbiome is now recognised as a key regulator of host metabolism — influencing energy harvest, bile acid metabolism, short-chain fatty acid production, and systemic inflammation.
- 16S rRNA and shotgun metagenomics — Gut microbial community profiling; alpha and beta diversity analysis; differential abundance testing with ANCOM-BC2 and LEfSe
- Functional microbiome profiling — Metabolic pathway abundance with HUMAnN3; SCFA biosynthesis gene quantification; bile acid biotransformation pathway mapping
- Microbiome-metabolome integration — Correlation and mediation analysis linking gut microbial taxa to circulating and faecal metabolite levels; multi-omics network construction
- Microbiome-host transcriptome association — Linking gut microbiome composition to host hepatic, adipose, and intestinal gene expression changes
- Dietary intervention microbiome studies — Longitudinal microbiome profiling; responder vs. non-responder analysis based on microbial baseline composition
8. Multi-Omics Integration for Metabolic Research MOFA+ · SNF · iCluster · Mediation
The full complexity of metabolic disease cannot be captured by any single omics layer. Our multi-omics integration service combines genomics, transcriptomics, proteomics, metabolomics, epigenomics, and microbiome data to build a comprehensive molecular model of metabolic disease.
- MOFA+ — Unsupervised latent factor discovery across genomic, transcriptomic, proteomic, and metabolomic datasets
- Multi-omics patient stratification — Similarity Network Fusion (SNF) and iCluster for metabolic disease subtype discovery with clinical outcome linkage
- Causal mediation analysis — Linking genetic variants to metabolite levels to clinical metabolic outcomes via transcriptomic and proteomic intermediaries
- Drug target prioritisation — Integrating GWAS, eQTL, pQTL, and mQTL data with pathway analysis to identify and rank novel metabolic drug targets
Key Applications
Research and translational applications across metabolic and endocrine disease.
- Type 2 diabetes genetic architecture and beta cell biology
- Obesity and adipose tissue dysfunction research
- Non-alcoholic fatty liver disease (NAFLD / NASH) molecular profiling
- Thyroid disorder genomics and transcriptomics
- Polycystic ovary syndrome (PCOS) multi-omics analysis
- Insulin resistance and metabolic syndrome biomarker discovery
- Lipid metabolism and dyslipidaemia genomics
- Adrenal and pituitary disorder characterisation
- Dietary and nutritional intervention omics studies
- Rare inherited metabolic disorder diagnosis
- Drug target identification for metabolic disease
- Metabolic biomarker panel development and validation
Our Analytical Workflow
A structured, reproducible process from initial data assessment to final interpreted results and written report.
Step 1 — Project Scoping Free
We discuss your study design, sample types, omics platforms, and research questions to define the most appropriate analytical approach and deliverables.
Step 2 — Data Receipt & QC
Secure encrypted data transfer; comprehensive QC across all omics data types before any analysis begins.
Step 3 — Pipeline Configuration
Version-controlled pipeline setup; tool selection matched to your data types, tissue context, and analytical goals.
Step 4 — Primary Analysis
Variant calling, expression quantification, metabolite feature detection, or protein abundance estimation as appropriate for each data type.
Step 5 — Statistical Analysis
Differential analysis, association testing, enrichment analysis, and biomarker identification with appropriate correction for multiple testing and confounders.
Step 6 — Pathway & Network Analysis
Metabolic pathway enrichment, co-expression network construction, and multi-omics factor analysis for mechanistic interpretation.
Step 7 — Visualisation
Publication-ready figures — volcano plots, heatmaps, pathway maps, PLS-DA score plots, metabolite network diagrams, and UMAP embeddings.
Step 8 — Report & Manuscript Support Optional
Full written report with methods, results, and biological interpretation; optional manuscript methods section and figure legend preparation.
Tools & Technologies
Validated, peer-reviewed, and actively maintained tools across all metabolism and endocrinology pipelines.
- GWAS & Genetics: PLINK2, REGENIE, SAIGE, LDpred2, TwoSampleMR
- RNA-seq: STAR, DESeq2, edgeR, limma, WGCNA, clusterProfiler
- scRNA-seq: Seurat, Scanpy, Cell Ranger, Monocle3, CellChat
- Metabolomics: XCMS, MZmine, MetaboAnalyst, LipidSearch
- Proteomics: MaxQuant, Perseus, Proteome Discoverer
- Epigenomics: bismark, ChAMP, MACS3, chromVAR, TOBIAS
- Microbiome: DADA2, MetaPhlAn4, HUMAnN3, ANCOM-BC2
- Multi-Omics Integration: MOFA+, SNF, iCluster, MixOmics
- Pathway Analysis: GSEA, fGSEA, MetaboAnalyst, ReactomePA
- Fine-mapping: SuSiE, FINEMAP, coloc, LDSC
- Mendelian Randomisation: TwoSampleMR, MendelianRandomization
- Spatial Transcriptomics: SpaceRanger, Squidpy, cell2location
- Visualisation: ggplot2, ComplexHeatmap, Seaborn, MetaboAnalyst
- Workflow: Snakemake, Nextflow, CWL
Reference Databases We Use
All major metabolism and endocrinology reference resources for comprehensive biological annotation and pathway interpretation.
- HMDB (Human Metabolome Database) — Comprehensive metabolite chemical, biological, and clinical information for metabolite identification and annotation
- KEGG — Metabolic pathway maps, enzyme-gene associations, and disease pathway definitions for enrichment analysis
- Reactome — Curated human metabolic and signalling pathway database for pathway enrichment and network analysis
- LIPID MAPS — Lipid classification, structural database, and lipidomics standards for lipid species annotation
- MetaCyc / BioCyc — Experimentally validated metabolic pathways across organisms for functional annotation
- GTEx v8 — Tissue-specific eQTL data for metabolic tissue gene expression colocalisation with GWAS signals
- IEU Open GWAS — Summary statistics repository for Mendelian randomisation and genetic correlation analyses
- gnomAD v4 — Population allele frequencies for rare variant filtering in metabolic disease gene panels
- OMIM / Orphanet — Gene-disease associations for inherited metabolic disorder variant interpretation
Project Deliverables
A complete, structured set of outputs ready for publication, grant submission, or translational application.
- Quality control report covering all omics data types and samples
- Processed data files: normalised expression matrices, annotated metabolite tables, filtered VCF files, or protein abundance tables
- Differential analysis results with effect sizes, confidence intervals, and FDR-corrected p-values
- Publication-ready figures (PDF, SVG, PNG at 300 dpi)
- Full written report: methods, results, biological interpretation, and recommendations
- Pipeline scripts and configuration files for full reproducibility
- Post-delivery consultation call for results walkthrough and Q&A
- Mendelian randomisation causal inference report
- Polygenic risk score development and validation report
- Manuscript methods section and figure legends (journal-formatted)
- Supplementary data tables and extended figure sets
- Custom R Shiny multi-omics explorer for interactive data browsing
- Long-term retainer support for ongoing or longitudinal metabolic cohort studies
Why Choose BioinformaticsNext?
Deep domain expertise combined with validated, scalable multi-omics pipelines — delivering results that are biologically meaningful, statistically rigorous, and publication-ready.
Metabolic Disease Expertise
Our analysts understand the biology of metabolic and endocrine disorders — from insulin signalling to lipid metabolism and hormonal regulation — ensuring your data is interpreted in its full biological context.
End-to-End Service
From raw omics data to final interpreted results — every step handled in-house with no need for your own bioinformatics infrastructure.
Validated Pipelines
All workflows follow published best-practice guidelines. Every tool version is recorded and all results are fully reproducible.
Fast Turnaround
Most projects are delivered within 2–4 weeks. Rush turnarounds are available for grant deadlines and clinical study timelines.
Multi-Omics Capability
We integrate genomics, transcriptomics, proteomics, metabolomics, epigenomics, and microbiome data — providing a holistic molecular view of metabolic disease that no single omics approach can deliver.
Flexible Engagement
Project-based, hourly, or long-term retainer arrangements tailored to your timeline and budget with no minimum commitment.
Data Security
Encrypted data transfer and storage. NDAs and GDPR-compliant Data Processing Agreements available upon request.
Global Reach
UK-headquartered with clients across Europe, North America, the Middle East, and Asia-Pacific.
Frequently Asked Questions
Common questions from metabolism and endocrinology research clients.
We work with plasma, serum, urine, faeces, tissue biopsies, cell culture media, and cerebrospinal fluid. Each sample type has specific pre-analytical requirements and we provide guidance on optimal collection, storage, and preparation protocols during the project scoping call.
Yes. Untargeted metabolomics provides broad coverage of the metabolome for hypothesis-free discovery, while targeted metabolomics quantifies specific predefined metabolite panels with higher precision and sensitivity. We support both approaches and can advise on which is most appropriate for your research question and sample type.
Absolutely. Multi-omics integration is one of our core strengths. We routinely integrate metabolomics with RNA-seq, GWAS, proteomics, and microbiome data using MOFA+, correlation networks, and mediation analysis to build comprehensive molecular models of metabolic phenotype — identifying causal relationships that cannot be detected from any single data type.
Yes. We have extensive experience analysing longitudinal omics data from dietary intervention trials, exercise studies, pharmacological treatment experiments, and disease progression cohorts. We apply appropriate mixed model and repeated measures statistical frameworks to account for within-subject correlations and time-course effects.
Yes. Biomarker discovery and validation is a key application of our service. We apply machine learning approaches (random forest, LASSO, elastic net), ROC analysis, and cross-validation frameworks to identify and evaluate candidate biomarkers from multi-omics datasets — delivering ranked biomarker lists with performance metrics.
Absolutely. We assist with the bioinformatics and multi-omics sections of grant applications — including study design, power calculations, proposed analytical workflows, and preliminary data generation. Please get in touch as early as possible in the grant preparation process.
Related Research Areas & Services
Metabolism and endocrinology intersects with multiple other research domains we support.
- Genetics & Genomics — GWAS, rare variant analysis, Mendelian randomisation, and polygenic risk score development for metabolic and endocrine traits
- Cancer & Oncogenomics — Metabolic reprogramming in cancer; Warburg effect; oncometabolite profiling and metabolic vulnerability identification
- Microbiology & Metagenomics — Gut microbiome contributions to metabolic disease; microbial metabolite profiling and microbiome-host metabolic axis analysis
- Immunology & Immuno-Oncology — Immunometabolism; adipose tissue inflammation; metabolic regulation of immune cell function in obesity and diabetes
- Custom Software & Pipeline Development — Bespoke metabolic data portals, biomarker reporting tools, and automated multi-omics pipeline deployment
Ready to Advance Your Metabolic Research?
Tell us about your samples, your omics data, and your research questions. Our metabolism and endocrinology team will design a tailored analytical plan — typically within 48 hours of your enquiry. Whether you are profiling metabolites in a clinical cohort, integrating multi-omics data from a dietary intervention trial, or identifying drug targets in a metabolic disease model, we are here to support you from day one.
